RAG (Retrieval-Augmented Generation) é uma arquitetura que melhora a eficácia dos grandes modelos de linguagem (LLMs) ao adicionar um sistema de recuperação de informações. Esse sistema fornece dados relevantes e atualizados que ajudam o modelo a gerar respostas mais precisas e contextualizadas.
A arquitetura RAG possui três pilares principais:
Criação da Base de Conhecimento (Data Load): Processo de carregamento e organização dos dados que serão utilizados.
Recuperação de Informação (Query): Busca de documentos relevantes que correspondem ao texto consultado.
Core: Responsável pela lógica de processamento, montagem do contexto e fornecimento da resposta final.
Criação da base de conhecimento
Para que o RAG funcione de maneira eficaz, é necessário ter uma base de dados indexada vetorialmente. Esse processo pode ser realizado manualmente, com um usuário fazendo upload de arquivos, ou de forma automatizada. A ideia é dividir os arquivos em chunks (trechos menores) e calcular embeddings para cada um desses chunks. Esses embeddings são então armazenados em um VectorDB, juntamente com metadados relevantes para o caso de uso.
Por exemplo, pode ser interessante salvar o BoundingBox do texto como metadado. Isso permite que, no futuro, seja possível fazer uma marcação precisa no documento durante o resultado a busca.
Veja um exemplo real de um VectorDB usando PgVector
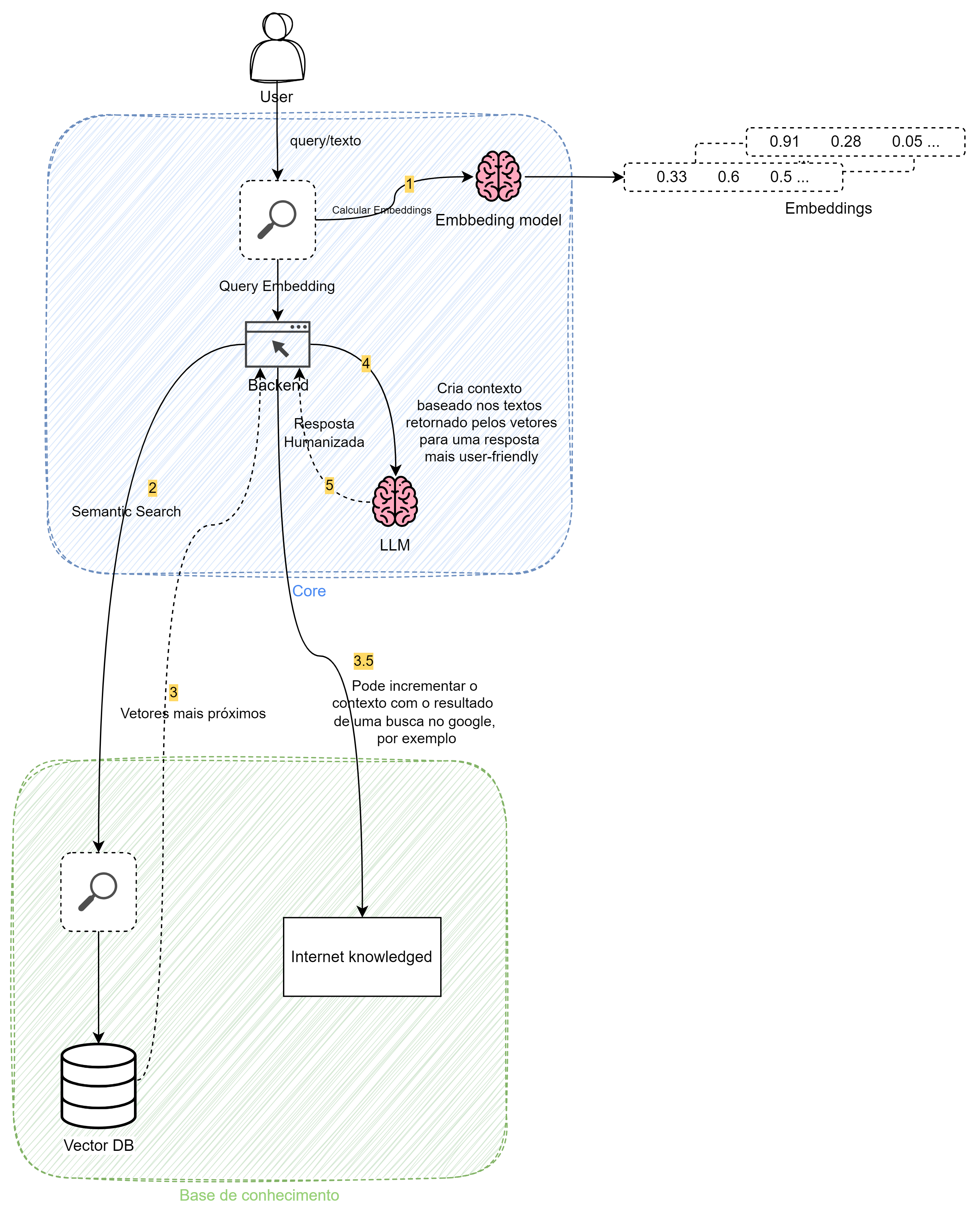
Recuperação de informação e Core
A descrição do funcionamento a seguir está numerada em amarelo na imagem a cima
Quando o usuário faz uma busca textual (como em um campo de busca tipo Google) em algum front-end, esse texto é enviado para o backend, onde é convertido em um embedding (vetor) usando um modelo de deep learning (embedding model). Existem vários modelos disponíveis no mercado, como:
text-ada-embedding-002
Word2Vec
FastText
Esse vetor (embedding) é então usado para buscar trechos de documentos relacionados na base de conhecimento (Vector Database). Os trechos mais relevantes são retornados, e é possível enriquecer esse contexto com outras informações, como resultados de buscas na internet.
A seguir, cria-se um contexto baseado nesses textos, levando em consideração o número máximo de tokens de entrada do LLM utilizado. Esse contexto é então passado para um LLM com o objetivo de gerar uma resposta adequada para o usuário final.
A arquitetura RAG trouxe a possibilidade de fornecer um contexto específico para um LLM, guiando a resposta dentro desse contexto. Isso é uma grande vantagem, pois atualizar constantemente um LLM com conteúdo recente é custoso. Com o RAG, podemos adicionar esse conteúdo de forma dinâmica. No entanto, há algumas desvantagens: cada LLM tem um limite de tokens de entrada e saída, o que limita a quantidade de contexto que pode ser passado, e quanto maior o contexto, maior o custo. Além disso, a forma como o contexto é montado é crucial para obter uma boa resposta; não basta simplesmente passar textos e esperar um bom resultado.
Vantagens:
Atualização Dinâmica: Permite a incorporação de informações atualizadas em tempo real, sem a necessidade de re-treinar o modelo.
Eficiência de Dados: Utiliza bases de dados externas para fornecer respostas, reduzindo a necessidade de grandes quantidades de dados de treinamento.
Flexibilidade: Pode ser adaptado para diferentes domínios e contextos rapidamente, apenas ajustando a base de dados de recuperação.
Desvantagens:
Dependência de Fontes Externas: A qualidade das respostas depende da qualidade e relevância das fontes de dados externas.
Latência: Pode haver um aumento na latência devido ao tempo necessário para recuperar e processar as informações.
Complexidade: A integração de sistemas de recuperação e geração pode ser complexa e exigir mais recursos computacionais.
O que não te falam?
Existem alguns pontos importantes sobre a arquitetura RAG que nem sempre são mencionados:
Pesquisa com TF-IDF: Realizar uma pesquisa inicial com TF-IDF e depois ranquear os resultados usando a distância vetorial do Vector Database pode melhorar a acurácia das respostas.
Qualidade do Prompt: O prompt do contexto precisa ser bem elaborado para evitar alucinações. Além disso, prompts mais complexos aumentam o custo, pois adicionam mais tokens como input no modelo LLM.
Dependência de Vector Stores: Armazenar embeddings em Vector Stores adiciona um custo extra e mais um ponto de falha na arquitetura.
Latência: As respostas tendem a ser mais lentas devido a:
Consulta a diversas bases de conhecimento.
Tempo necessário para calcular embeddings.
Tempo para calcular distâncias vetoriais (Busca Semântica).
Custo de Indexação: Indexar a base de conhecimento pode ser caro, pois envolve calcular embeddings usando um modelo.
Mudança de Modelo de Embedding: Alterar o modelo de embedding no futuro pode ser inviável, pois exigiria reprocessar toda a base de conhecimento. Escolha bem o modelo de embedding, pois ele impacta diretamente os resultados. Alguns modelos são melhores para tarefas específicas, como sumarização ou classificação. Para mais informações, veja: https://huggingface.co/spaces/mteb/leaderboard e https://www.mongodb.com/pt-br/developer/products/atlas/choose-embedding-model-rag/
Tamanho do Embedding: O modelo de embedding afeta diretamente o espaço de armazenamento necessário. Embeddings com mais dimensões requerem mais storage.
O que é TF-IDF? É uma das formas mais utilizadas (até hoje) para comparar textos. Ele é baseado na frequência das palavras. https://pt.wikipedia.org/wiki/Tf%E2%80%93idf
Par avaliar qual melhor modelo de embedding: MTEB leaderboard (https://huggingface.co/spaces/mteb/leaderboard)
Arquitetura Completa
Prompt Engineering vs RAG vs Fine-tune
Antes de começar com RAG, é importante avaliar se o seu caso de uso pode ser resolvido apenas com Prompt Engineering. Isso envolve passar instruções mais direcionadas para o modelo LLM. Se isso não for satisfatório, talvez seja necessário considerar Fine-Tuning ou RAG.
Prompt Engineering: Tentar ajustar o comportamento do modelo com instruções específicas. É uma abordagem rápida e eficiente quando o modelo já possui conhecimento suficiente sobre o assunto.
RAG (Retrieval-Augmented Generation): Funciona como uma “memória curta”. O modelo não tem aquele conhecimento específico, então você fornece o contexto necessário para ele se basear na resposta. Isso é útil para acessar informações atualizadas ou específicas que não estão na base de conhecimento original do modelo.
Fine-Tuning: Funciona como uma “memória longa”. O modelo é treinado com novos dados, internalizando esse conhecimento. Isso é ideal quando é necessário que o modelo se especialize em um tópico específico.
Para mais informações sobre prompt engineering veja:
A arquitetura RAG (Retrieval-Augmented Generation) é um avanço para os modelos de linguagem, permitindo que eles forneçam respostas mais precisas e relevantes. Ao juntar a geração de texto com a recuperação de informações, o RAG consegue acessar dados atualizados e específicos, melhorando a qualidade das respostas.