


Desvendando a GenAI - Parte 12
Implementando um RAG Simples

A arquitetura RAG (Retrieval-Augmented Generation) combina técnicas de recuperação de informações com modelos de linguagem para criar respostas contextualmente relevantes. Este post apresenta uma implementação simples de um RAG no contexto de manutenção preventiva, demonstrando como unir uma base de conhecimento local e um modelo de linguagem para oferecer respostas mais precisas.
O exemplo usa apenas dados locais e não é ideal para produção. O objetivo é educativo, apresentando os conceitos básicos de RAG.
Visão Geral
A implementação consiste em três pilares principais:
Processamento e Construção da Base de Conhecimento: Transformar documentos em vetores para criar uma base de dados pesquisável.
Recuperação de Informações (Query): Buscar documentos relevantes com base na entrada do usuário.
Geração de Resposta (Core): Usar o contexto recuperado para construir uma resposta por meio de um modelo de linguagem.
Antes de continuar com a leitura a seguir, é importante que você tenha lido o post anterior desta série.

Código Fonte: Construindo o RAG
Aqui está o código completo comentado e estruturado para facilitar o entendimento:
Configuração Inicial
import os
import numpy as np
from openai import OpenAI
from dotenv import load_dotenv
import ell
import faiss # pip install faiss ou pip install faiss-cpu
## Para executar usando OpenAI
# Carregando variáveis de ambiente a partir do arquivo .env
# load_dotenv(r".env")
# OPENAI_SERVICE_ACCOUNT_KEY = os.getenv("OPENAI_SERVICE_ACCOUNT_KEY")
# # Configurar a chave da API
# client = OpenAI(api_key=OPENAI_SERVICE_ACCOUNT_KEY)
## Para executar usando Ollama (gratuito) => veja como instalar aqui https://ollama.com/
MODEL = "llama3.1"
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama",
)
ell.config.verbose = True
ell.config.register_model(MODEL, client)Para usar o Ollama é preciso baixar o modelos antecipadamente. Para isso, execute os seguintes comandos no prompt/terminal.
ollama pull llama3.1
ollama pull
all-minilm
Função de Embedding
def calculate_embbeding(text: str) -> list[float]:
"""
Converte um texto em um vetor. Esses vetores podem ser usados para serem armazenados em uma base de vetores por exemplo.
"""
return (
# client.embeddings.create(input=text, model="text-embedding-ada-002")
client.embeddings.create(input=text, model="all-minilm")
.data[0]
.embedding
)Construção da Base de Conhecimento
def create_kb(corpora: list[str]) -> faiss.IndexFlatL2:
"""
Função responsável por criar base de conhecimento. Calcular embedding e inserir no banco
"""
# Gerar embeddings para os documentos
document_embeddings = [calculate_embbeding(doc) for doc in corpora]
embeddings = np.array(document_embeddings).astype("float32")
# Criar um índice FAISS
dimension = embeddings.shape[1] # Número de dimensões dos vetores
index = faiss.IndexFlatL2(dimension) # Usando a métrica L2 (distância euclidiana)
index.add(embeddings) # Adicionar embeddings ao índice
return indexBusca de Documentos
def search_in_kb(query: str, corpora: list[str], kb: faiss.IndexFlatL2) -> list[str]:
"""
Dado um texto, busca na base de conhecimento os dois documentos mais próximos
"""
query_vector = np.array([calculate_embbeding(query)]).astype("float32") # Consulta
distances, indices = kb.search(
query_vector, k=2
) # Retorna os 2 vetores mais próximos
result = []
for i in indices[0]:
result.append(corpora[i])
return resultGeração da Resposta Final
# @ell.simple(model="gpt-4o-mini", client=client)
@ell.simple(model="llama3.1", client=client)
def generate_final_response(similar_docs: list[str], query: str):
context = ""
for doc in similar_docs:
context += doc + "\n\n --- \n\n"
return [
ell.system("Baseada no contexto responda a pergunta fornecida."),
ell.user(
f"""Contexto:
{context}
Fim do Contexto
###
{query}"""
),
]Exemplo de Execução
Base de Conhecimento
# Base de conhecimento de manutenção preventiva da empresa.
# No mundo real esse corpora é composto pelo conteúdo de aquivos que foram parseados (pdf, excel, docx, txt...) e servirão como base de conhecimento.
corpora = [
"O código de erro E102 indica superaquecimento do motor. Verifique o nível de óleo e o sistema de resfriamento.",
"Recomenda-se trocar o óleo do gerador a cada 250 horas de operação ou a cada 6 meses, o que ocorrer primeiro. Verifique também o filtro de óleo a cada troca.",
"Como calibrar uma balança industrial? Para calibrar a balança, coloque pesos padrão sobre a plataforma e ajuste o visor para refletir o peso correto. Repita o processo em diferentes pontos de carga.",
"O que deve ser inspecionado em uma empilhadeira antes de usá-la? Verifique o nível de combustível ou carga da bateria, o funcionamento dos pneus, a integridade dos freios, a carga máxima permitida e os controles hidráulicos.",
]Observe que nossa base de conhecimento consiste apenas em strings. Em um sistema mais complexo, nossa base de conhecimento é uma combinação de arquivos, dados em bancos de dados e diversas outras fontes. A complexidade do RAG muitas vezes reside em como acessar essas fontes, fazer o parser e montar o contexto.
Consulta e Resposta
# Input do usuário
query = "O que significa o erro E102?"
## Com base no post https://andredemattosferraz.substack.com/p/desvendando-a-genai-parte-11 estes seriam os três pilares do RAG
# Pilar 1 => Processaento do arquivo + Construção da base de conhecmento
kb = create_kb(corpora)
# Pilar 2 => Recuperação de Informação (Query)
similar_docs = search_in_kb(query, corpora, kb)
# Pilar 3 => Core
response = generate_final_response(similar_docs, query)
print(response)
response = generate_final_response([], query) # avaliando resposta sem contexto
print(response)Resultado
Com contexto:
“Eror 102 é um código de superaquecimento de motor. Ele indica que há problema no sistema de resfriamento ou no nível do óleo no Motor, e deve ser verificado se está ativo.”
Sem contexto:
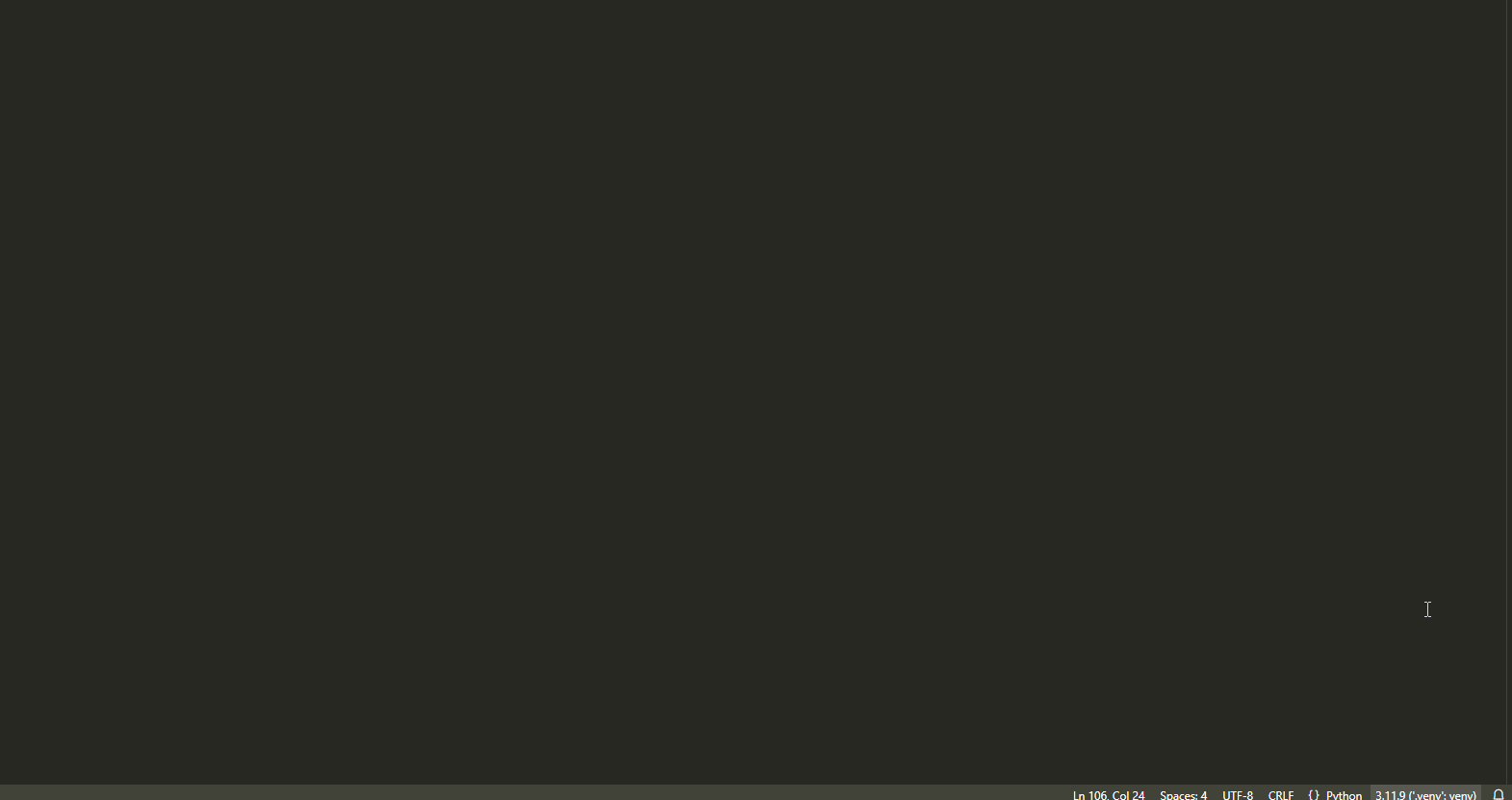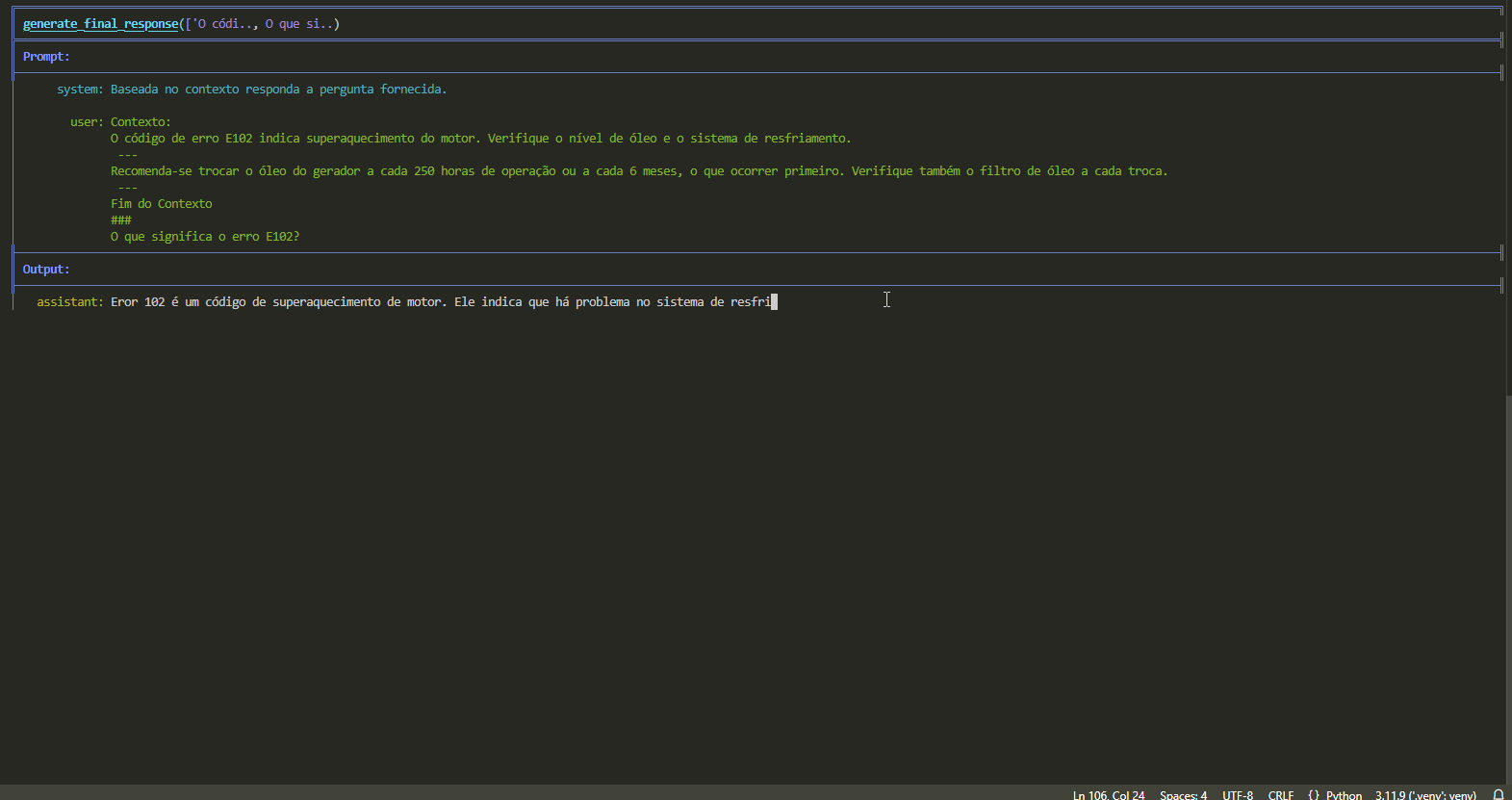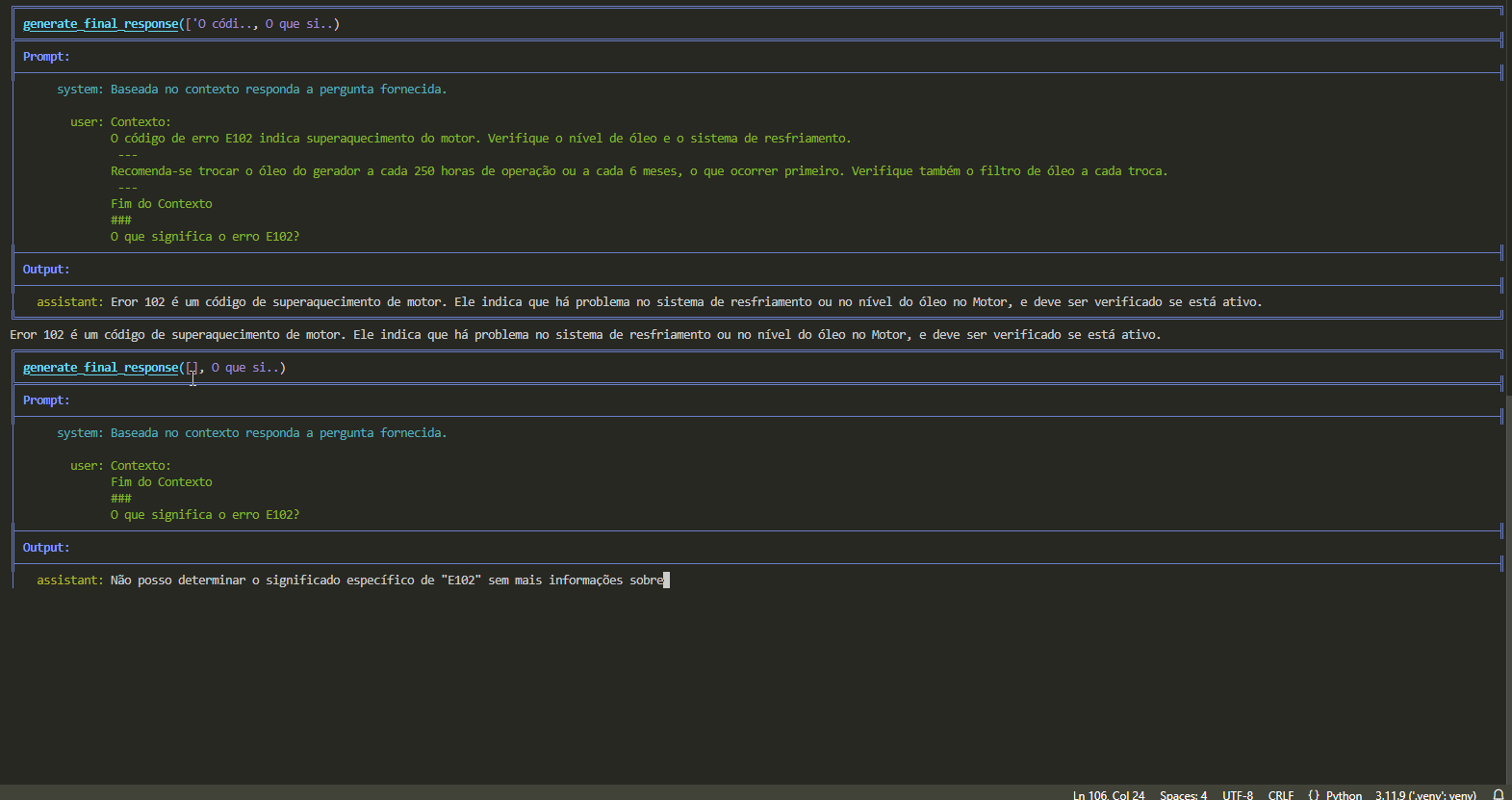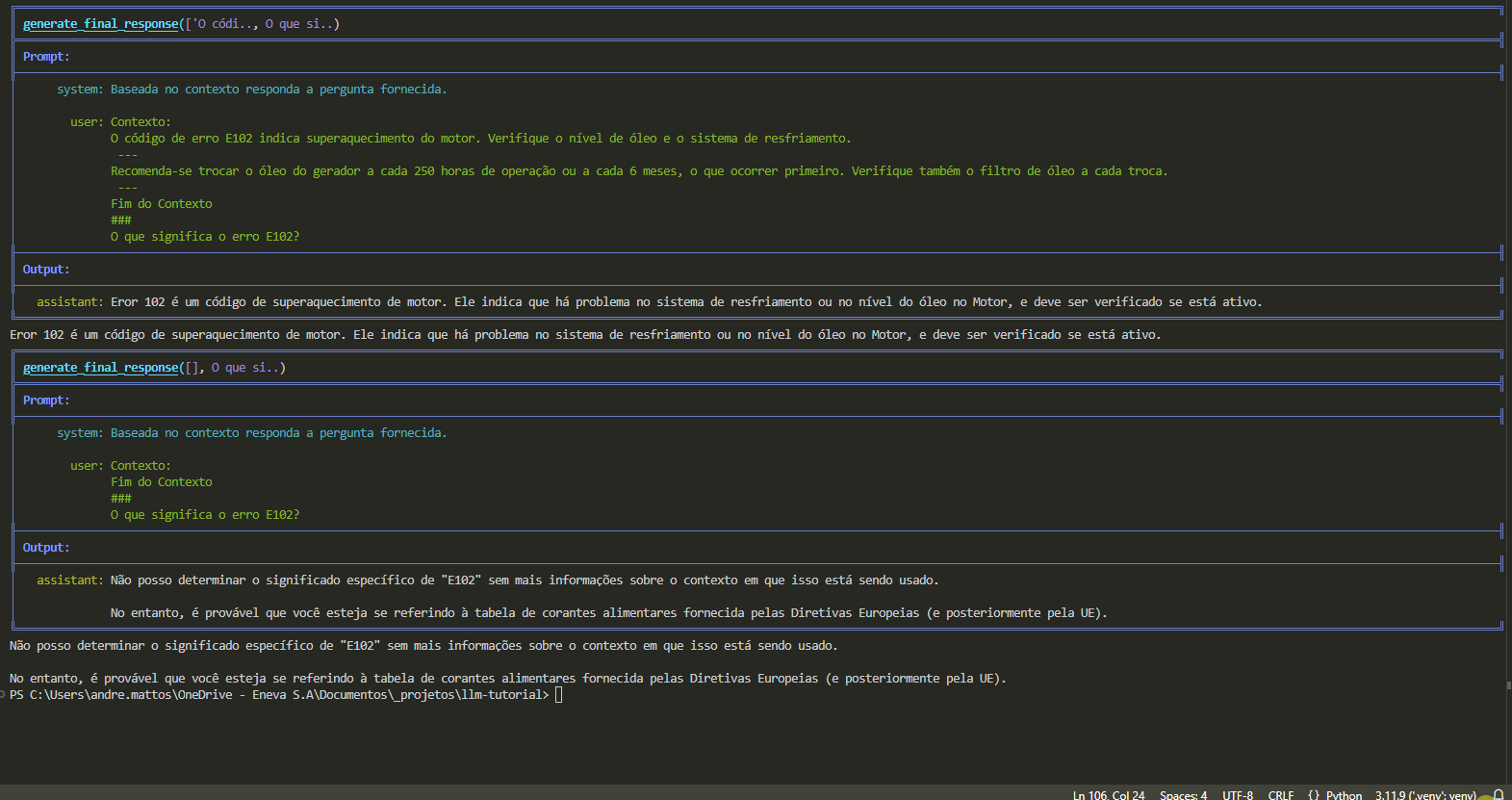
Não posso determinar o significado específico de "E102" sem mais informações sobre o contexto em que isso está sendo usado.
No entanto, é provável que você esteja se referindo à tabela de corantes alimentares fornecida pelas Diretivas Europeias (e posteriormente pela UE).
Conclusão
Este exemplo mostra como a arquitetura RAG pode integrar recuperação de informações e modelos de linguagem para resolver problemas reais. Apesar de sua simplicidade, a estrutura é dinâmica e pode ser ampliada para cenários mais complexos com fonte de dados mais complexas.